
Karmada作为开源的云原生多云容器编排项目,吸引了众多企业共同参与项目开发,并运行于生产环境中。同时多云也逐步成为数据中心建设的基础架构,多区域容灾与多活、大规模多集群管理、跨云弹性与迁移等场景推动云原生多云相关技术的快速发展。
一、 背景
随着vivo业务不断迁移到k8s上,集群规模和集群的数量快速增长,运维难度也急剧增加。为了构建多集群技术,我们也自研了多集群管理,但无法解决我们遇到的更多的问题。后来开始对社区相关项目做了细致的调研和测试,我们最终选择了Karmada。
主要原因如下:
具备对多套K8s集群的统一管理能力,业务通过服务维度去管理资源,降低容器平台的管理难度。
跨集群的弹性伸缩和调度能力,实现跨集群的资源合理利用,从而提升资源利用率并节约成本。
Karmada完全使用了K8s原生的API,改造成本低。
容灾,Karmada控制平面与member集群解藕,集群异常时支持资源重新分配。
可扩展性,如可以添加自研的调度插件和添加自研Openkruise解释器插件等。
在我们探索怎么使用Karmada的同时,我们也遇到了Karmada自身运维的问题。
社区部署工具较多,需要用户自己选择。当前用户部署方式如下:
Karmadactl
Karmada charts
二进制部署
hack目录下脚本
对于上面的几种工具,在Karmada的社区开展了问卷调研,并生成了统计报告。
主要总结如下:
社区部署工具较多,需要用户自己选择。
部署脚本也存在缺陷,需要用户自己解决,github上关于这方面的提问较多。
黑屏化操作,没有提供k8s api操作,用户难以产品化,我们主要期望对接我们的容器平台,实现可视化安装。
缺少CI测试和部署工具的发布计划。
etcd集群缺少生产环境的关键功能点,如etcd的高可用、定期备份和恢复。
需要安装很多依赖插件,涉及到Karmada控制平面、Karmada的host集群和member集群。
缺少一键部署和配置繁琐等痛点。
针对以上问题,本文将分享Karmada-Operator的vivo实践,包括Operator的方案选择、API、架构设计和CI构建等。
二、Karmada-Operator的落地实践
2.1 Operator SDK介绍
Operator Framework 是一个开源工具包,用于以有效、自动化且可扩展的方式管理 Kubernetes 原生应用程序,即 Operator。Operator 利用 Kubernetes 的可扩展性来展现云服务的自动化优势,如置备、扩展以及备份和恢复,同时能够在 Kubernetes 可运行的任何地方运行。
Operator 有助于简化对 Kubernetes 上的复杂、有状态的应用程序的管理。然而,现在编写 Operator 并不容易,会面临一些挑战,如使用低级别 API、编写样板文件以及缺乏模块化功能(这会导致重复工作)。
Operator SDK 是一个框架,通过提供以下内容来降低 Operator 的编写难度:
高级 API 和抽象,用于更直观地编写操作逻辑
支架和代码生成工具,用于快速引导新项目
扩展项,覆盖常见的 Operator 用例
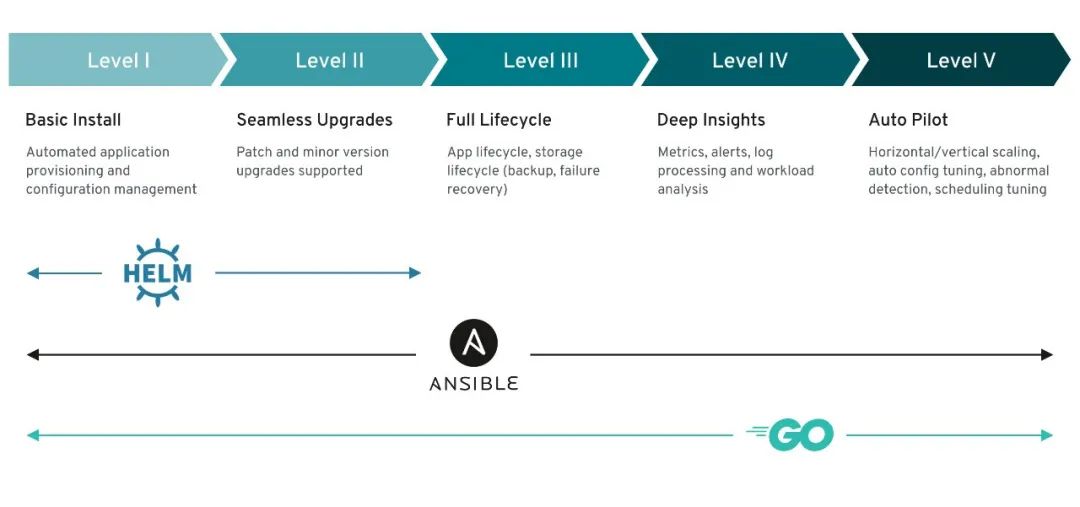
如上图所示,operator sdk可以基于helm、ansilbe和go构建operator,我们需根据当前的情况选择我们合适的operator框架。
2.2 方案选择
方案一:golang 开发Operator
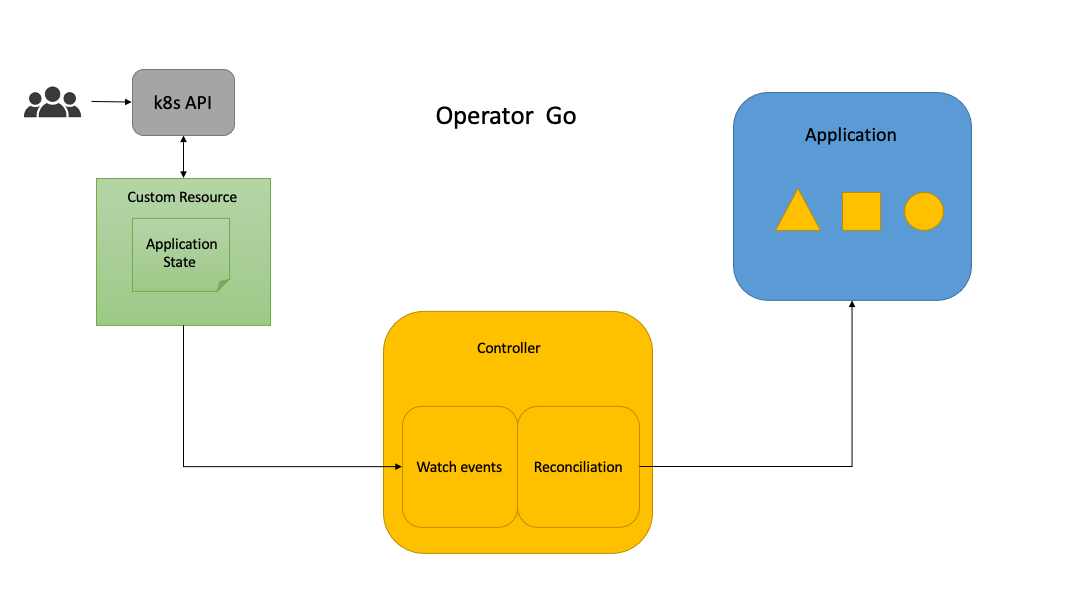
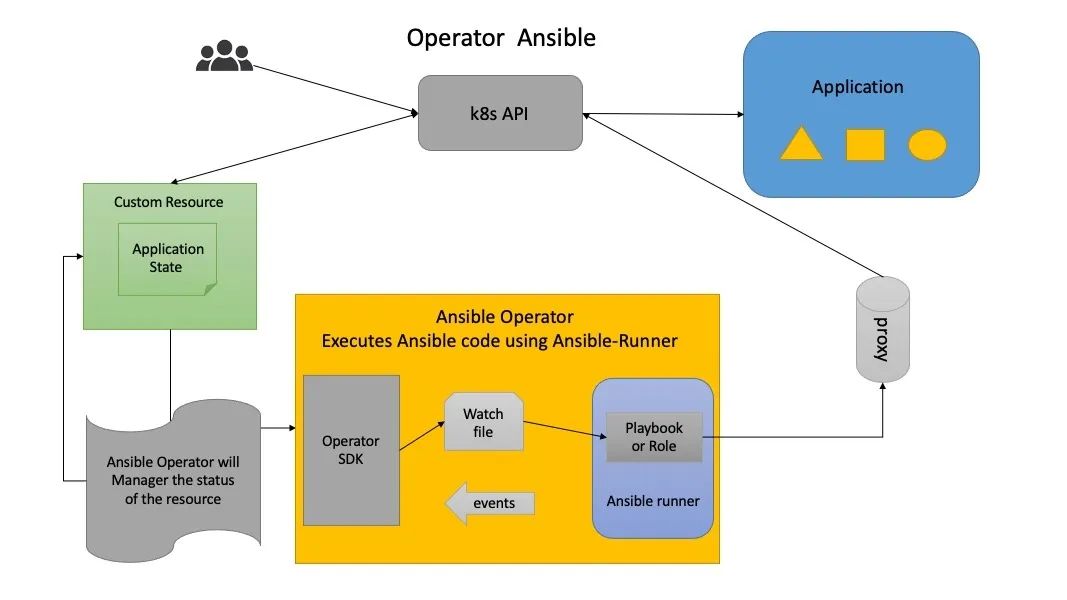
方案二:ansible开发Operator
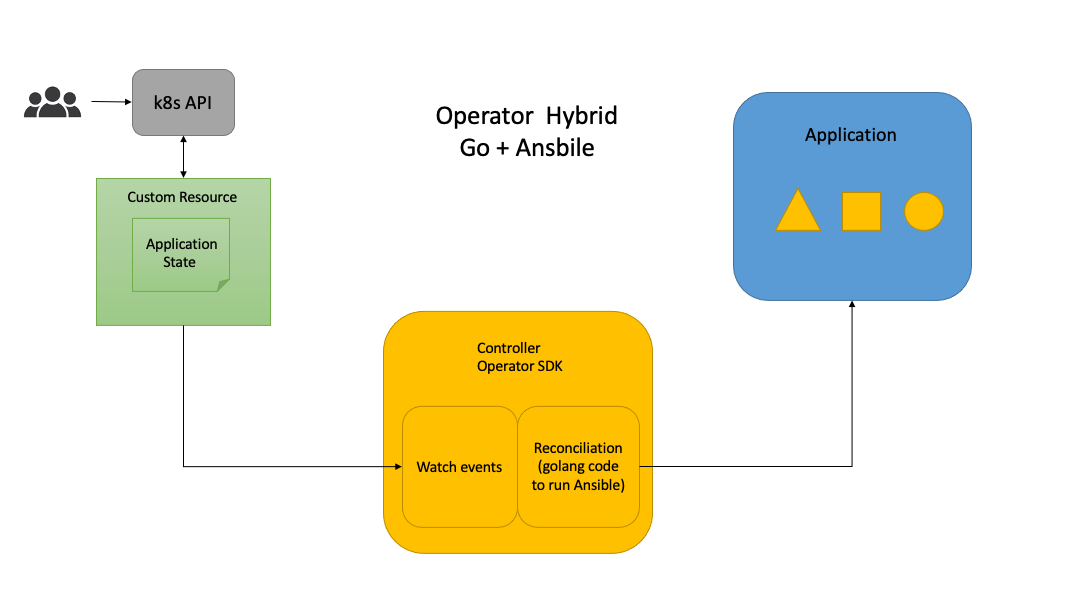
方案三:golang和ansible混合开发Operator
根据Karmada的实际生产部署调研情况和vivo自身的实践,可以总结如下:
要支持在K8s集群和不依赖K8s集群二进制部署。
支持外部独立的etcd集群部署或者对接已有的etcd集群。
Karmada集群具备迁移能力,如机房裁撤和机器故障等,就需要etcd集群管理有备份和恢复能力,如根据etcd备份数据快速在其它机房恢复集群。
需要支持第三方的vip给Karmada-apiserver提供负载均衡,目前vivo都是基于外部vip,并提供了域名。没有使用K8s的service给Karmada-apiserver提供负载均衡。
Karmada控制平面一键部署和member集群的自动化注册和注销。也需要获取member集群的kubeconfig,pull模式也需要在member集群部署Karmada-agent。
Karmada集群的addons插件安装,如istio、anp、第三方的crd等安装,需要在Karmada的控制平面、host主机集群,甚至需要在member集群上进行配置。
提供api能力,实现可视化部署。
针对Karmada单个组件的单独升级和全量升级。
支持在offline和离线模式。
面对Karmada如此复杂的条件限制,我们再来分析下上面3个方案谁可能比较合适。
方案一,基于go开发的Operator,比较适合基于K8s集群的有状态服务管理,如etcd,数据库等,比较成熟的有etcd-Operator。Karmada涉及到不依赖K8s集群二进制部署、外部etcd、member集群的注册、注销和插件安装,不能很好的支持或者需要增加开发量。
方案二,基于ansible开发的Operator,既可以基于K8s集群的对状态服务管理,也可以脱离K8s集群对如不依赖K8s集群二进制部署、外部etcd、member集群的注册、注销和插件安装。这里主要通过ansible 的ssh登录能力和K8s模块管理,通过调研我们也发现90%以上的用户可以提供ssh登录。
方案三,基于go+ansible的混合的Operator,读者可以阅读vivo开发的Kubernetes-Operator,就是基于这种方案。方案三具备方案二的所有能力,因为底层都是通过ansible去执行。
首先我们排除了方案一,对于方案二和方案三,本人也纠结了很长是时间,最终我们选择了方案二。主要原因如下:
Operator SDK ansible已具备了和Operator SDK go相等的能力,并提供K8s、K8s_status模块、相似的webhook功能去对k8s的资源管理,以及reconciliation的能力。
符合目前Karmada实际生产部署的需求。
简单易学,只要知道ansbile的jinja模版、和K8s相同的yaml文件。你只需要编写ansible task,开箱即用,reconciliation由Operator SDK 解决。
对于常用ansible的人比较友好,不需要写golang代码。
扩展能力强,用户可自定义插件。管理端也支持local、ssh、zeromq三种方式连接。local模式可以直接对接K8s接口,ssh模式可以登录执行脚本。可以很好的混合使用,解决我们当前的需求。
Karmada运维操作相对K8s要简单,不需要复杂的crd定义,ansible需要解析少量vars去执行playbook就行。golang+ansible模式比较适合复杂CRD定义和业务逻辑复杂的系统。
2.3 API设计
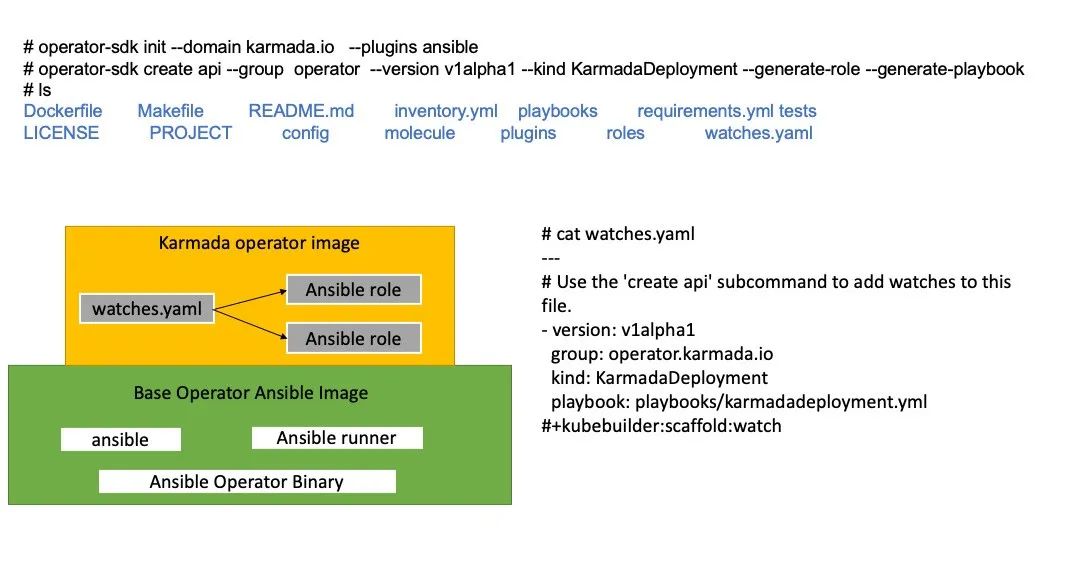
如上图所示,我们只需要执行Operator-SDK create api命令,就可以创建 KarmadaDeployment的CRD,然后就可以定义KarmadaDeployment的API。在watches.yaml里实现Reconcile的业务逻辑。

这里主要定义KarmadaDeployment、EtcdBackup和EtcdRestore个资源,分别用于Karmada的部署,和etcd的数据备份和恢复。ansible Operator会根据spec里定义解析成ansible的vars。status将通过 ansible runner 输出为用户自定义的状态。也可以通过ansible的k8s_status更新KarmadaDeployment的状态。当前主要考虑的是在K8s运行Karmada,后面会添加二进制部署模式,当前的CR没有涉及。
2.4 架构设计
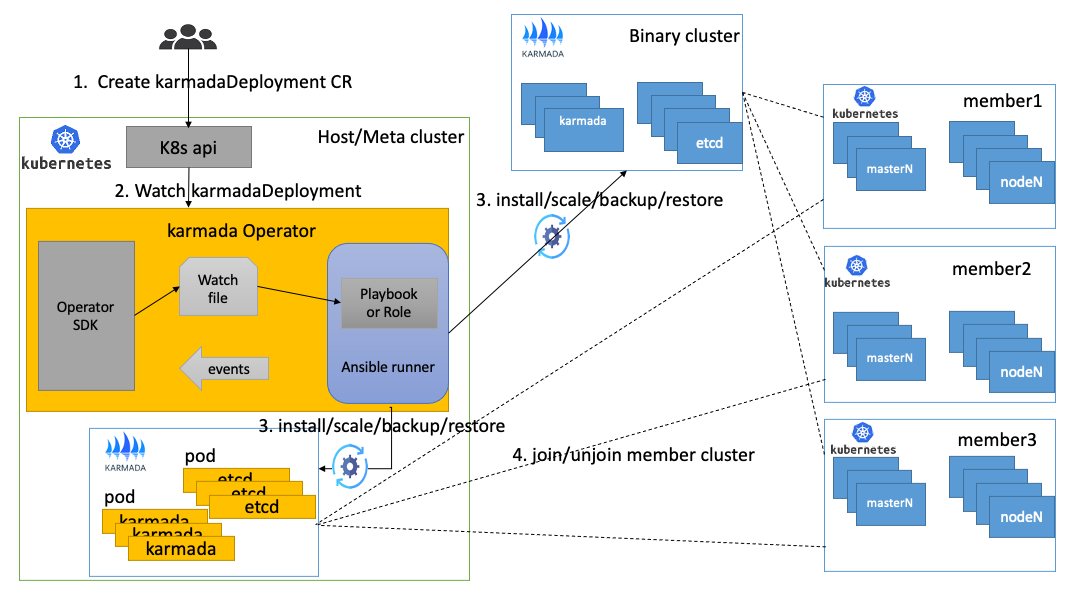
如图所示Karmada Operator提供了容器化和二进制集群部署设计,其中Karmada的容器化部署不需要执行ssh登录,只需通过K8s和k8s_status就可以完成karmada控制面的管控。Karmada的二进制部署主要通过ssh登录完成Karmada控制平面的管控。member集群的join和unjoin需要提前提供member集群的kubeconfig文件,也可以设置member的登录权限操作,需要在CR里定义member集群的用户和密钥。
执行流程如下。
用户通过KarmadaDeployment定义Karmada操作
Karmada Operator感知KarmadaDeployment的CR变化,开始进入控制器逻辑
根据用户的定义,选择是容器化部署或者二进制部署,开始执行安装、扩所容和备份等操作
执行join/unjoin操作,将member集群注册到Karmada集群或者注销member集群
2.5 Karmada控制平面管理
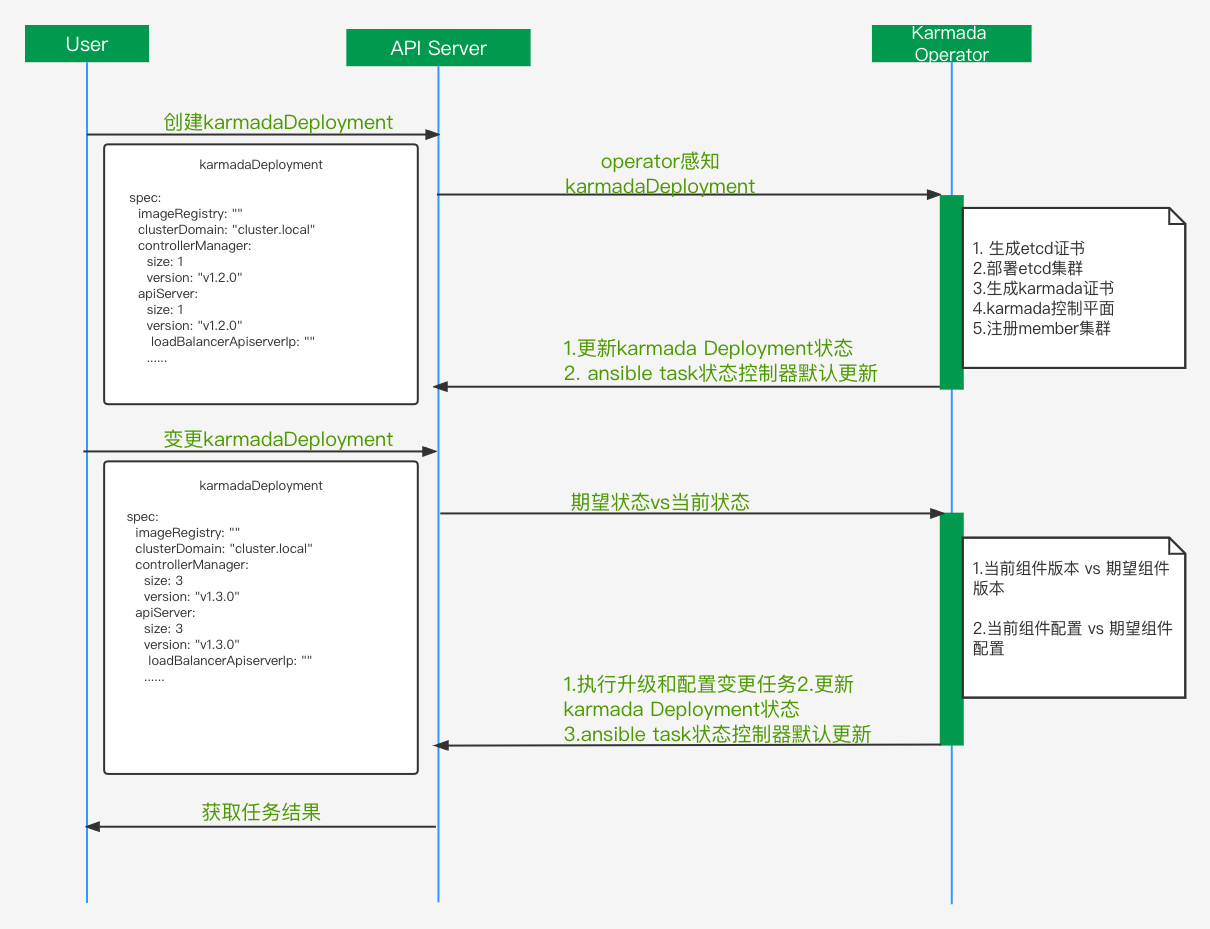
如上图所示,主要是karmada控制平面生命周期管理,对比当前社区的部署工具我们如下优化:
标准化证书管理,主要是用openssl生成证书。其中etcd和Karmada证书单独分开维护,和k8s集群证书命名相同,方便接入我们的监控。
Karmada-apiserver支持外部负载均衡,不限于当前的k8s service提供的负载均衡。
更灵活的升级策略,支持单独组件升级和全量升级。
更丰富的全局变量定义,计划支持组件配置变更等。
2.6 etcd集群管理
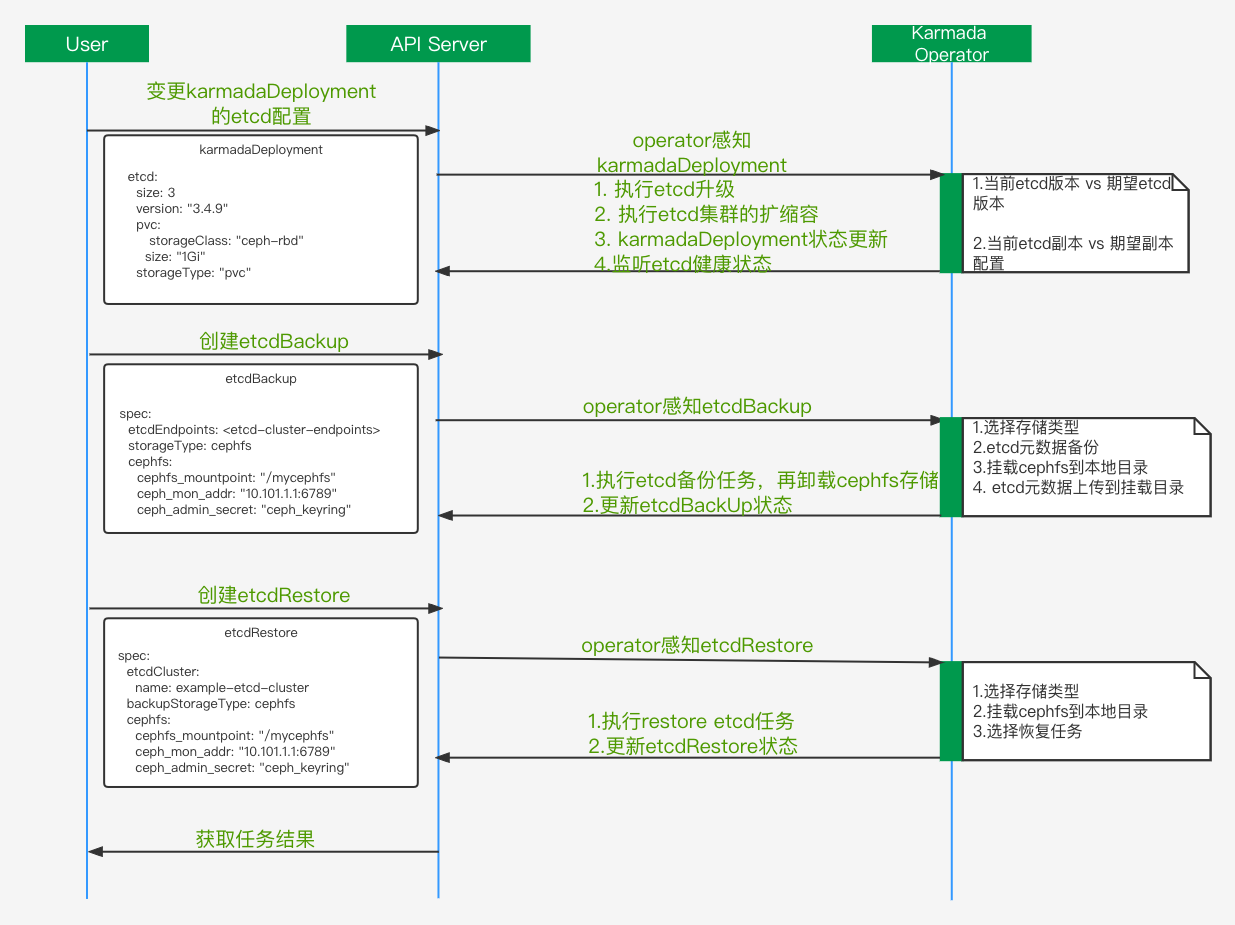
etcd集群是Karmada的元数据集群,生产中需要保证etcd集群高可用和故障恢复等。如上图展示了etcd集群必要的生产要素,如自动扩缩容、升级、备份和etcd集群的故障恢复。自研了基于ansible的plugins和library, 实现etcd集群管理能力如下:
添加member到存在的etcd集群。
etcd集群删除member。
etcd集群的备份,比如支持cephfs的数据备份。
etcd集群故障恢复。
etcd集群健康状态查询。
这里定义了etcdBackup和etcdRestore的CR,没有合并到KarmadaDeployment里。主要考虑到etcd集群本身操作的安全性和简化KarmadaDeployment的ansible任务。其中etcdRestore功能,可以根据etcd集群备份数据,实现导入到新的etcd集群,从而恢复Karmada集群所有的业务状态。当前主要场景如下:
Karmada集群所在的机房裁撤,需要备份etcd数据,迁移到新的Karmada集群。
期望通过Karmada-Operator管理Karmada集群,只需备份etcd数据,实现etcdRestore功能即可。
Karmada集群故障,可以通过etcd备份数据,结合etcdRestroe实现故障恢复。
2.7 member集群管理
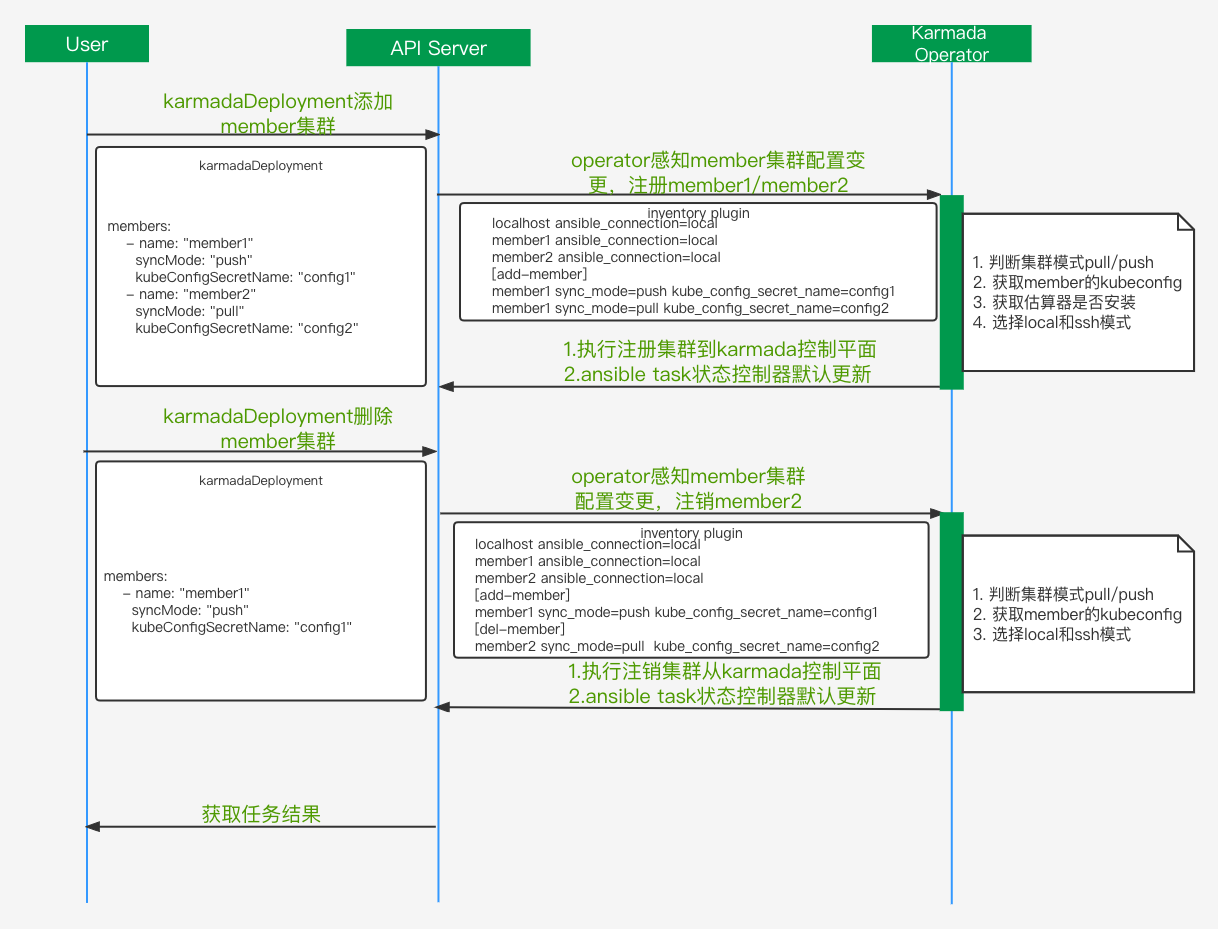
member集群的生命周期管理主要有注册和注销,上图是执行的流程。为了处理member集群的注册和注销,这里会动态的生成inventory。Ansible Inventory 是包含静态 Inventory 和动态 Inventory 两部分的,静态 Inventory 指的是在文件中指定的主机和组,动态 Inventory 指通过外部脚本获取主机列表,并按照 ansible 所要求的格式返回给 ansilbe 命令的。
这里Karmada-Operator基于k8s的CR实现了动态inventory plugins,主要通过解析KarmadaDeployment的members定义去动态的生成inventory。这里添加了add-member和del-member 2个角色, add-member里集群会被注册到Karmada控制平面,del-member里的集群会被从Karmada控制平面注销,这样就可以并发的注册和注销多个member集群。同时也可以提供ssh登录模式,方便后期扩展。
三、Karmada-Operator的CI介绍
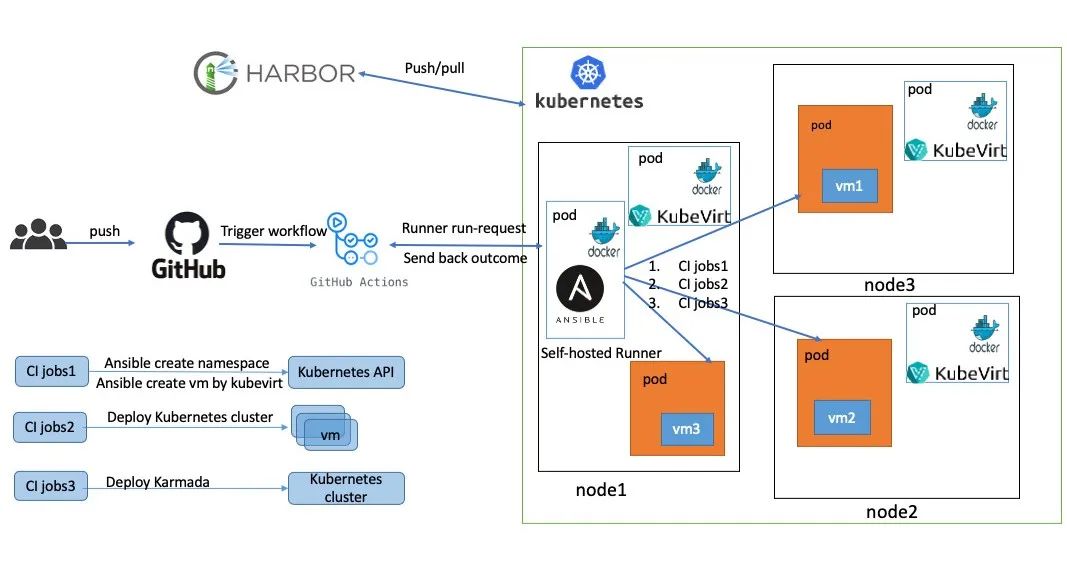
为了更好的提高开发人员的体验,计划提供Karmada-Operator的CI构建能力。这里在K8s集群里部署github的self-hosted Runner和kubevirt。
用户在github上提交PR
触发github Actions,我们在self-hosted里定义的流程
执行语法和单元测试
通过kubevirt创建vm
在多个vm里部署1个host和2个member集群
部署Karmada和添加member集群
执行Karmada e2e和bookfinfo案例测试
计划添加的CI矩阵测试如下:
语法测试:
ansible-lint
shellcheck
yamllint
syntax-check
pep8
集群部署测试:
Karmadactl、charts、yaml和二进制部署和所有配置项安装测试
join/ unjoin member 集群
升级Karmada
etcd集群的备份和恢复
功能测试:
Karmada e2e测试
创建bookinfo案例
性能测试:
我们主要通过kubemark组件模拟了多个2000节点的member集群进行了性能测试,其中一个测试案例是集群故障转移,结论是4w个无状态pod能够在15分钟完成故障迁移,有机会可以分享我们的性能测试。
四、总结
通过社区的调研和vivo的实践,最终确定了Karmada-Operator方案设计。Karmada-Operator具有高度可扩展性、可靠性、更直观地编写操作逻辑和开箱即用等特点,我们相信通过这种高度可扩展的声明式、自我修复云原生系统管理Karmada,为我们全面切换到Karmada去管理业务提供了强有力可靠保障。
基于ansible的operator也存在如下缺点。第一点没有提供webhook的能力,需要自己添加或者在ansible的task添加相关的校验;第二点是自动生成了通用的CRD模版,没有详细可定义的脚手架工具去自动生成CRD。
当前Karmada-operator还在初始阶段,提供了方案和部分实践,具体功能还需不断的完善和改进。具体可以查看vivo的Karmada-Operator仓库,欢迎大家试用和提建议。当前代码提供的能力矩阵可以查看项目规划。

