
2025年3月28日,上海移动联合华为发布了基于DeepSeek的核心网MoM(Mixture of Model)运维智能体试点方案,开创性地将快思考、慢思考大模型混合架构融入运维领域,实现了网络事件的智能化分级处理,简单问题“快”响应,复杂推理“慢”思考。传统通信大模型在处理如分类和总结等简单问题时优势明显,但在处理如时序数据异常识别和故障诊断等逻辑推理类任务时比较乏力。此次双方在DeepSeek推理大模型方面的合作探索,旨在有效解决“快思考”的直觉陷阱,实现复杂问题的深度处理,为核心网运维转型注入新的动力,标志着核心网运维智能体正式进入了新阶段。
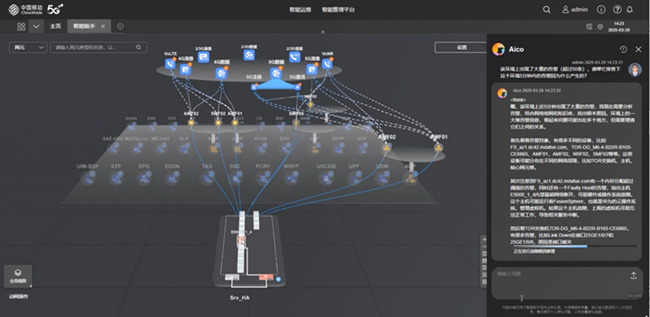
上海移动和华为基于对核心网运维领域的深刻理解,以及在大模型/智能体技术方面丰富的技术和实践积累,围绕核心网运维的关键痛点和场景,积极探索DeepSeek在核心网运维专业的应用,首创了真正适用于核心网运维领域的MoM(Mixture of Model)智能体架构,充分整合了传统通信大模型快思考和DeepSeek推理类大模型的慢思考优势。
简单问题“快”响应:针对告警处理,投诉分析,配置生成等高频场景所需的分类、提参和总结类任务,基于通信专业模型实现快思考,秒级输出结果,并保证90%以上的准确率。
复杂推理“慢”思考:针对网络变更,网络优化,日常运维分析等场景所需的规划、推理类任务,基于DeepSeek推理模型实现强逻辑思考规划,辅助运维人员实现复杂任务处理。
一次思考,长期收益:新场景第一次通过慢思考形成思维链(CoT:Chain of Thought),后续类似问题可以基于CoT实现快输出,实现系统整体效率最优。
相对于传统的单模型智能体架构,MoM可以突破场景限制,实现核心网6大运维场景(告警处理、投诉处理、应急抢通、网络变更、业务开通、日常运维)全场景AI+覆盖。上海移动和华为首阶段创新围绕“基于自然语言推理的告警压缩”、“基于强推理的时序数据异常识别”和“基于思维链CoT的故障诊断”三大价值场景展开,应用后预计平均推理时延降低50%,资源消耗降低30%。
基于自然语言推理的告警压缩:日常运维中常常会出现因网络异常导致的海量网元告警,数量短时间内可能达到万级,运维人员需要快速判断根因告警的收敛、压缩、根因溯源,压力巨大。通过引入DeepSeek的强推理能力,实现网络拓扑自动理解,千级告警分钟级溯源,缓解运维人员在处理海量告警问题时的压力。
基于强推理的时序数据异常识别:核心网的KPI数据属于典型的时序数据,很多故障现象和业务变化等都隐藏在时序数据中,传统处理方式需要人工借助专用的工具进行时序数据的分析,从中找到异常根因或者规律。DeepSeek的引入实现了对时序数据的自动、例行分析,借助强大的代码生成能力,同步实现异常数据图表的可视化。
基于思维链CoT的故障诊断:面向KPI劣化等复杂故障场景,传统方式主要依赖运维专家基于经验和故障线索进行推演,存在耗时长、技能要求高等问题。DeepSeek引入后,通过KPI劣化场景定界CoT激发DeepSeek在核心网运维领域定界的强推理能力,实现异常线索的快速推理,在初期给运维人员提供诊断建议,后期经过长期的CoT积累和运营后实现KPI劣化场景自动诊断。
上海移动与华为此次在核心网MoM(Mixture of Model)智能体架构上的技术突破破解了运维领域的“效率-精度”悖论,标志着核心网运维智能体进入了新的阶段。面向未来,中国移动与华为将持续加大在大模型和智能体等新技术方面的探索投入,最大程度激发AI在核心网运维方面潜力,推动核心网加速迈向自智网络(AN)L4。
